Researchers used CRISPR-based assays to develop new clinical laboratory point-of-care blood test which boasts accuracy, affordability, and accessibility
According to UPI, the test can “distinguish between influenza A and influenza B—the two main types of seasonal flu—as well as identifying more virulent strains like H1N1 and H3N2.”
Many research teams are working to develop paper-based diagnostic screening tests because of their lower cost to produce and usefulness in remote locations. Should this near-patient point-of-care test become clinically viable, it could mean shorter times to answer, enabling speedier diagnoses and earlier start of treatment.
It also means patient specimens do not have to be transported to a clinical laboratory for testing. And reduced cost per test makes it possible to test more people. This serves the public health aspect of monitoring outbreaks of influenza and other diseases and gives hope for improved treatment outcomes.
“Being able to tease apart what strain or subtype of influenza is infecting a patient has repercussions both for treating them and public health interventions, said Jon Arizti Sanz, PhD, co-lead study author and postdoctoral researcher at the Broad Institute of Harvard and MIT, in a Broad Institute news release.
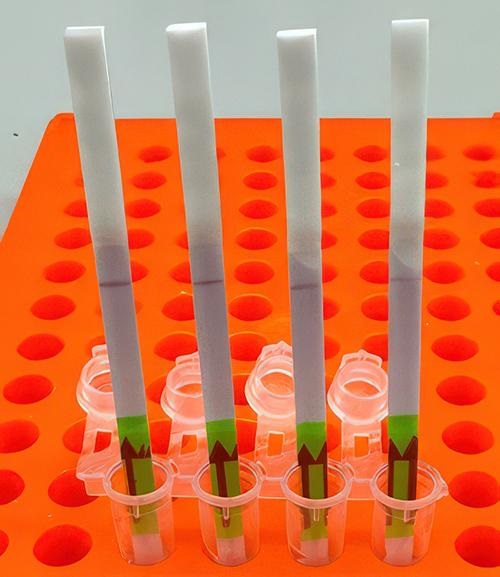
“Ultimately, we hope these tests will be as simple as rapid antigen tests, and they’ll still have the specificity and performance of a nucleic acid test that would normally be done in a laboratory setting,” Cameron A. Myhrvold, PhD (above), Assistant Professor of Molecular Biology at Princeton University in New Jersey, told CIDRAP. Influenza tests that can be performed at the point of care and in remote locations may reduce the number of screening tests performed by clinical laboratories. (Photo copyright: Michael James Butts/Hertz Foundation.)
Her team developed their tests using Streamlined Highlighting of Infections to Navigate Epidemics (SHINE), “a clustered regularly interspaced short palindromic repeats (CRISPR)-based RNA detection platform,” the researchers wrote in their Journal of Molecular Diagnostics paper.
“SHINE has a runtime of 90 minutes, can be used at room temperature and only requires an inexpensive heat block to heat the reaction. The SHINE technology has previously been used to identify SARS-CoV-2 and later to distinguish between the Delta and Omicron variants,” Bioanalysis Zone reported.
“The test uses genetically engineered enzymes to identify specific sequences of viral RNA in samples,” the researchers told UPI. Originally designed to detect COVID-19, the team adapted the technology to detect influenza in 2022 “with the aim of creating a screening tool that could be used in the field or in clinics rather than hospitals or high-tech diagnostic labs,” they said.
Influenza A and B as well as H1N1 and H3N2 subtypes were the targets of the four SHINE assays. “When tested on clinical samples, these optimized assays achieved 100% concordance with quantitative RT-PCR. Duplex Cas12a/Cas13a SHINE assays were also developed to detect two targets simultaneously,” the researchers wrote in their paper.
The team used “20 nasal swabs from people with flu-like symptoms during the 2020-2021 flu season, nasal fluid from healthy people as the control, and 2016-2021 influenza sequences downloaded from the National Center for Biotechnology Information Influenza (NICB) database. They compared the results with those from quantitative reverse transcription-polymerase chain reaction (RT-PCR) tests,” CIDRAP reported.
The original 2020 test (shown above) takes 90 minutes to develop at room temperature. The test developers aim to drop this down to 15 minutes. In comparison, typical polymerase chain reaction (PCR) testing requires medical laboratories to have specialized equipment, trained staff, and prolonged processing times, the Broad Institute news release notes. (Photo copyright: Broad Institute.)
Implications of the New Tests
The ease of the new tests is an important development since approximately only 1% of individuals who come down with the flu see doctors for testing, according to the news release. And researchers had this in mind, looking at speed, accuracy, and affordability as a means to “improve outbreak response and infection care around the world,” UPI reported.
There are great benefits to strain differentiation that be achieved with the new test. Doctors are hopeful the test will help dial in the best treatment plans for patients since some strains are resistant to the antiviral medication oseltamivir (Tamiflu), UPI noted. This is significant since Tamiflu “is a common antiviral,” said Sanz in the Broad Institute news release.
“These assays have the potential to expand influenza detection outside of clinical laboratories for enhanced influenza diagnosis and surveillance,” the Journal of Molecular Diagnostics paper noted. This allows for more strategic treatment planning.
“Using a paper strip readout instead of expensive fluorescence machinery is a big advancement, not only in terms of clinical care but also for epidemiological surveillance purposes,” said Ben Zhang, an MD candidate in the Health Sciences and Technology at Harvard and co-first author of the study, in the Broad Institute news release.
Future Plans for Tests
“With further development, the test strip could be reprogrammed to distinguish between SARS-CoV-2 and flu and recognize swine flu and avian flu, including the H5N1 subtype currently causing an outbreak in US dairy cattle,” the study authors told CIDRAP.
The team is also looking at ways to help prevent H5N1 from crossing into human contamination, Sanz told UPI.
The new Princeton/MIT/Harvard tests echo the trend to bring in affordability and ease-of-use with accurate results as an end goal. Faster results mean the best treatments for each person can start sooner and may render the transport of specimens to a clinical laboratory as a second step unnecessary.
As research teams work to develop paper-based viral tests for their plethora of benefits, clinical laboratories will want to pay close attention to this development as it can have a big implication on assisting with future outbreaks.
Additional research is needed before these tests are going to be commonplace in homes worldwide, but this first step brings inspiration and hope of what’s to come.
The ASBMB story notes that nanopore technology depends on differences in charges on either side of the membrane to force DNA or RNA through the hole. This is one reason why proteins pose such a challenge.
“Think of a cell as a miniature city, with proteins as its inhabitants. Each protein-resident has a unique identity, its own characteristics, and function. If there was a database cataloging the fingerprints, job profiles, and talents of the city’s inhabitants, such a database would undoubtedly be invaluable!” said Behzad Mehrafrooz, PhD (above), Graduate Research Assistant at University of Illinois at Urbana-Champaign in an article he penned for the university website. This research should be of interest to the many clinical laboratories that do protein testing. (Photo copyright: University of Illinois.)
How the Maglia Process Works
In a Groningen University news story, Maglia said protein is “like cooked spaghetti. These long strands want to be disorganized. They do not want to be pushed through this tiny hole.”
His technique, developed in collaboration with researchers at the University of Rome Tor Vergata, uses electrically charged ions to drag the protein through the hole.
“We didn’t know whether the flow would be strong enough,” Maglia stated in the news story. “Furthermore, these ions want to move both ways, but by attaching a lot of charge on the nanopore itself, we were able to make it directional.”
The researchers tested the technology on what Maglia described as a “difficult protein” with many negative charges that would tend to make it resistant to flow.
“Previously, only easy-to-thread proteins were analyzed,” he said in the news story. “But we gave ourselves one of the most difficult proteins as a test. And it worked!”
Maglia now says that he intends to commercialize the technology through a new startup called Portal Biotech.
Detecting Post-Translational Modifications in the UK
In another recent study, researchers at the University of Oxford reported that they have adapted nanopore technology to detect post-translational modifications (PTMs) in protein chains. The term refers to changes made to proteins after they have been transcribed from DNA, explained an Oxford news story.
“The ability to pinpoint and identify post-translational modifications and other protein variations at the single-molecule level holds immense promise for advancing our understanding of cellular functions and molecular interactions,” said contributing author Hagan Bayley, PhD, Professor of Chemical Biology at University of Oxford, in the news story. “It may also open new avenues for personalized medicine, diagnostics, and therapeutic interventions.”
Bayley is the founder of Oxford Nanopore Technologies, a genetic sequencing company in the UK that develops and markets nanopore sequencing products.
The news story notes that the new technique could be integrated into existing nanopore sequencing devices. “This could facilitate point-of-care diagnostics, enabling the personalized detection of specific protein variants associated with diseases including cancer and neurodegenerative disorders,” the story states.
In another recent study, researchers at the University of Washington reported that they have developed their own method for protein sequencing with nanopore technology.
“This opens up the possibility for barcode sequencing at the protein level for highly multiplexed assays, PTM monitoring, and protein identification!” Motone wrote.
Single-cell proteomics, enabled by nanopore protein sequencing technology, “could provide higher sensitivity and wider throughput, digital quantification, and novel data modalities compared to the current gold standard of protein MS [mass spectrometry],” they wrote. “The accessibility of these tools to a broader range of researchers and clinicians is also expected to increase with simpler instrumentation, less expertise needed, and lower costs.”
There are approximately 20,000 human genes. However, there are many more proteins. Thus, there is strong interest in understanding the human proteome and the role it plays in health and disease.
Technology that makes protein testing faster, more accurate, and less costly—especially with a handheld analyzer—would be a boon to the study of proteomics. And it would give clinical laboratories new diagnostic tools and bring some of that testing to point-of-care settings like doctor’s offices.
Best of all, the researchers say the test could provide an inexpensive means of early diagnosis. This assay could also be used to monitor how well patients respond to cancer therapy, according to a news release.
The protein had previously been identified as a promising biomarker and is readily detectable in tumor tissue, they wrote. However, it is found in extremely low concentrations in blood plasma and is “well below detection limits of conventional clinical laboratory methods,” they noted.
To overcome that obstacle, they employed an ultra-sensitive immunoassay known as a Simoa (Single-Molecule Array), an immunoassay platform for measuring fluid biomarkers.
“We were shocked by how well this test worked in detecting the biomarker’s expression across cancer types,” said lead study author gastroenterologist Martin Taylor, MD, PhD, Instructor in Pathology, Massachusetts General Hospital and Harvard Medical School, in the press release. “It’s created more questions for us to explore and sparked interest among collaborators across many institutions.”
“We’ve known since the 1980s that transposable elements were active in some cancers, and nearly 10 years ago we reported that ORF1p was a pervasive cancer biomarker, but, until now, we haven’t had the ability to detect it in blood tests,” said pathologist and study co-author Kathleen Burns, MD, PhD (above), Chair of the Department of Pathology at Dana-Farber Cancer Institute and a Professor of Pathology at Harvard Medical School, in a press release. “Having a technology capable of detecting ORF1p in blood opens so many possibilities for clinical applications.” Clinical laboratories may soon have a new blood test to detect multiple types of cancer. (Photo copyright: Dana-Farber Cancer Institute.)
Simoa’s Advantages
In their press release, the researchers described ORF1p as “a hallmark of many cancers, particularly p53-deficient epithelial cancers,” a category that includes lung, breast, prostate, uterine, pancreatic, and head and neck cancers in addition to the cancers noted above.
“Pervasive expression of ORF1p in carcinomas, and the lack of expression in normal tissues, makes ORF1p unlike other protein biomarkers which have normal expression levels,” Taylor said in the press release. “This unique biology makes it highly specific.”
Simoa was developed at the laboratory of study co-author David R. Walt, PhD, the Hansjörg Wyss Professor of Bioinspired Engineering at Harvard Medical School, and Professor of Pathology at Harvard Medical School and Brigham and Women’s Hospital.
The Simoa technology “enables 100- to 1,000-fold improvements in sensitivity over conventional enzyme-linked immunosorbent assay (ELISA) techniques, thus opening the window to measuring proteins at concentrations that have never been detected before in various biological fluids such as plasma or saliva,” according to the Walt Lab website.
Simoa assays take less than two hours to run and require less than $3 in consumables. They are “simple to perform, scalable, and have clinical-grade coefficients of variation,” the researchers wrote.
Study Results
Using the first generation of the ORF1p Simoa assay, the researchers tested blood samples of patients with a variety of cancers along with 406 individuals, regarded as healthy, who served as controls. The test proved to be most effective among patients with colorectal and ovarian cancer, finding detectable levels of ORF1p in 58% of former and 71% of the latter. Detectable levels were found in patients with advanced-stage as well as early-stage disease, the researchers wrote in Cancer Discovery.
Among the 406 healthy controls, the test found detectable levels of ORF1p in only five. However, the control with the highest detectable levels, regarded as healthy when donating blood, “was six months later found to have prostate cancer and 19 months later found to have lymphoma,” the researchers wrote.
They later reengineered the Simoa assay to increase its sensitivity, resulting in improved detection of the protein in blood samples from patients with colorectal, gastroesophageal, ovarian, uterine, and breast cancers.
The researchers also employed the test on samples from 19 patients with gastroesophageal cancer to gauge its utility for monitoring therapeutic response. Although this was a small sample, they found that among 13 patients who had responded to therapy, “circulating ORF1p dropped to undetectable levels at follow-up sampling.”
“More Work to Be Done”
The Simoa assay has limitations, the researchers acknowledged. It doesn’t identify the location of cancers, and it “isn’t successful in identifying all cancers and their subtypes,” the press release stated, adding that the test will likely be used in conjunction with other early-detection approaches. The researchers also said they want to gauge the test’s accuracy in larger cohorts.
“The test is very specific, but it doesn’t tell us enough information to be used in a vacuum,” Walt said in the news release. “It’s exciting to see the early success of this ultrasensitive assessment tool, but there is more work to be done.”
More studies will be needed to valid these findings. That this promising new multi-cancer immunoassay is based on a clinical laboratory blood sample means its less invasive and less painful for patients. It’s a good example of an assay that takes a proteomic approach looking for protein cancer biomarkers rather than the genetic approach looking for molecular DNA/RNA biomarkers of cancer.
Scientists believe useful new clinical laboratory assays could be developed by better understanding the huge number of ‘poorly researched’ genes and the proteins they build
Researchers have added a new “-ome” to the long list of -omes. The new -ome is the “unknome.” This is significant for clinical laboratory managers because it is part of an investigative effort to better understand the substantial number of genes, and the proteins they build, that have been understudied and of which little is known about their full function.
The Unknome Database includes “thousands of understudied proteins encoded by genes in the human genome, whose existence is known but whose functions are mostly not,” according to a news release.
The database, which is available to the public and which can be customized by the user, “ranks proteins based on how little is known about them,” the PLOS Biology paper notes.
It should be of interest to pathologists and clinical laboratory scientists. The fruit of this research may identify additional biomarkers useful in diagnosis and for guiding decisions on how to treat patients.
“These uncharacterized genes have not deserved their neglect,” said Sean Munro, PhD (above), MRC Laboratory of Molecular Biology in Cambridge, England, in a press release. “Our database provides a powerful, versatile and efficient platform to identify and select important genes of unknown function for analysis, thereby accelerating the closure of the gap in biological knowledge that the unknome represents.” Clinical laboratory scientists may find the Unknome Database intriguing and useful. (Photo copyright: Royal Society.)
Risk of Ignoring Understudied Proteins
Proteomics (the study of proteins) is a rapidly advancing area of clinical laboratory testing. As genetic scientists learn more about proteins and their functions, diagnostics companies use that information to develop new assays. But did you know that researchers tend to focus on only a small fraction of the total number of protein-coding DNA sequences contained in the human genome?
The study of proteomics is primarily interested in the part of the genome that “contains instructions for building proteins … [which] are essential for development, growth, and reproduction across the entire body,” according to Scientific American. These are all protein-coding genes.
Proteomics estimates that there are more than two million proteins in the human body, which are coded for 20,000 to 25,000 genes, according to All the Science.
To build their database, the MRC researchers ranked the “unknome” proteins by how little is known about their functions in cellular processes. When they tested the database, they found some of these less-researched proteins important to biological functions such as development and stress resistance.
“The role of thousands of human proteins remains unclear and yet research tends to focus on those that are already well understood,” said Sean Munro, PhD, MRC Laboratory of Molecular Biology in Cambridge, England, in the news release. “To help address this we created an Unknome database that ranks proteins based on how little is known about them, and then performed functional screens on a selection of these mystery proteins to demonstrate how ignorance can drive biological discovery.”
In the paper, they acknowledged the human genome encodes about 20,000 proteins, and that the application of transcriptomics and proteomics has “confirmed that most of these new proteins are expressed, and the function of many of them has been identified.
“However,” the authors added, “despite over 20 years of extensive effort, there are also many others that still have no known function.”
They also recognized limited resources for research and that a preference for “relative safety” and “well-established fields” are likely holding back discoveries.
The researchers note “significant” risks to continually ignoring unexplored proteins, which may have roles in cell processes, serve as targets for therapies, and be associated with diseases as well as being “eminently druggable,” Genetic Engineering News reported.
Setting up the Unknome Database
To develop the Unknome Database, the researchers first turned to what has already come to fruition. They gave each protein in the human genome a “knownness” score based on review of existing information about “function, conservation across species, subcellular localization, and other factors,” Interesting Engineering reported.
It turns out, 3,000 groups of proteins (805 with a human protein) scored zero, “showing there’s still much to learn within the human genome,” Science News stated, adding that the Unknome Database catalogues more than 13,000 protein groups and nearly two million proteins.
The researchers then tested the database by using it to determine what could be learned about 260 “mystery” genes in humans that are also present in Drosophila (small fruit flies).
“We used the Unknome Database to select 260 genes that appeared both highly conserved and particularly poorly understood, and then applied functional assays in whole animals that would be impractical at genome-wide scale,” the researchers wrote in PLOS Biology.
“We initially selected all genes that had a knownness score of ≤1.0 and are conserved in both humans and flies, as well as being present in at least 80% of available metazoan genome sequences. … After testing for viability, the nonessential genes were then screened with a panel of quantitative assays designed to reveal potential roles in a wide range of biological functions,” they added.
“Our screen in whole organisms reveals that, despite several decades of extensive genetic screens in Drosophila, there are many genes with essential roles that have eluded characterization,” the researchers conclude.
Clinical Laboratory Testing Using the Unknome Database
Future use of the Unknome Database may involve CRISPR technology to explore functions of unknown genes, according to the PLOS Biology paper.
Munro told Science News the research team may work with other research efforts aimed at understanding “mysterious proteins,” such as the Understudied Proteins Initiative.
The Unknome Database’s ability to be customized by others means researchers can create their own “knownness” scores as it applies to their studies. Thus, the database could be a resource in studies of treatments or medications to fight diseases, Chemistry World noted.
According to a statement prepared for Healthcare Dive by SomaLogic, a Boulder, Colorado-based protein biomarker company, diagnostic tests that measure proteins can be applied to diseases and conditions such as:
“The 27-protein model has potential as a ‘universal’ surrogate end point for cardiovascular risk,” the researchers wrote in Science Translational Medicine.
Proteomics definitely has its place in clinical laboratory testing. The development of MRC-LMB’s Unknome Database will help researchers’ increase their knowledge about the functions of more proteins which should in turn lead to new diagnostic assays for labs.
Research findings could lead to new biomarkers for genetic tests and give clinical laboratories new capabilities to diagnose different health conditions
New insights continue to emerge about “junk DNA” (aka, non-coding DNA). For pathologists and clinical laboratories, these discoveries may have value and eventually lead to new biomarkers for genetic testing.
One recent example comes from researchers at Stanford Medicine in California who recently learned how non-coding DNA—which makes up 98% of the human genome—affects gene expression, the function that leads to observable characteristics in an organism (phenotypes).
The research also could lead to a better understanding of how short tandem repeats (STRs)—the number of times a gene is copied into RNA for protein use—affect gene expression as well, according to Stanford.
“We’ve known for a while that short tandem repeats or STRs, aren’t junk because their presence or absence correlates with changes in gene expression. But we haven’t known how they exert these effects,” said study lead Polly Fordyce, PhD (above), Associate Professor of Bioengineering and Genetics at Stanford University, in a news release. The research could lead to new clinical laboratory biomarkers for genetic testing. (Photo copyright: Stanford University.)
To Bind or Not to Bind
In their Science paper, the Stanford researchers described an opportunity to explore a new angle to transcription factors binding to some sequences, also known as sequence motifs.
“Researchers have spent a lot of time characterizing these transcription factors and figuring out which sequences—called motifs—they like to bind to the most,” said the study lead Polly Fordyce, PhD, Associate Professor of Bioengineering and Genetics at Stanford University, in a Stanford Medicine news release.
“But current models don’t adequately explain where and when transcription factors bind to non-coding DNA to regulate gene expression. Sometimes, no transcription factor is attached to something that looks like a perfect motif. Other times, transcription factors bind to stretches of DNA that aren’t motifs,” the news release explains.
Transcription factors are “like light switches that can turn genes on or off depending on what cells need,” notes a King’s College LondonEDIT Labblog post.
But why do transcription factors target some places in the genome and not others?
“To solve the puzzle of why transcription factors go to some places in the genome and not to others, we needed to look beyond the highly preferred motifs,” Fordyce added. “In this study, we’re showing that the STR sequence around the motif can have a really big effect on transcription factor binding, providing clues as to what these repeated sequences might be doing.”
Such information could aid in understanding certain hereditary conditions and diseases.
“Variations in STR length have been associated with changes in gene expression and implicated in several complex phenotypes such as schizophrenia, cancer, autism, and Crohn’s disease. However, the mechanism by which STRs affect transcription remains unknown,” the researchers wrote in Science.
Special Assays Explore Binding
According to their paper, the research team turned to the Fordyce Lab’s previously developed microfluidic binding assays (MITOMI, k–MITOMI, and STAMMP) to analyze the impact of different DNA sequences on transcription factor binding.
“In the experiment we asked, ‘How do these changes impact the strength of transcription factor binding?’ We saw a surprisingly large effect. Varying the STR sequence around a motif can have a 70-fold impact on the binding,” Fordyce wrote.
In an accompanying Science article titled, “Repetitive DNA Regulates Gene Expression,” Thomas Kuhlman, PhD, Assistant Professor, Physics and Astronomy, University of California, Riverside, wrote that the study “demonstrates that STRs exert their effects by directly binding transcription factor proteins, thus explaining how STRs might influence gene expression in both normal and diseased states.”
“This research unveils, for the first time, the intricate connection between how variants in the non-coding genome affect genes that are associated with blood pressure and with hypertension. What we’ve created is a kind of functional map of the regulators of blood pressure genes, “said Philipp Maass, PhD, Lead Researcher and Assistant Professor Molecular Genetics, University of Toronto, in a news release.
The research team used massively parallel reporter assay (MPRA) technology to analyze 4,608 genetic variants associated with blood pressure.
The findings could aid precision medicine for cardiovascular health and may possibly be adopted to other conditions, according to The Hospital for Sick Children.
“The variants we have characterized in the non-coding genome could be used as genomic markers for hypertension, laying the groundwork for future genetic research and potential therapeutic targets for cardiovascular disease,” Maass noted.
Why All the ‘Junk’ DNA?
Clinical laboratory scientists may wonder why genetic research has primarily focused on 20,000 genes within the genome, leaving the “junk” DNA for later investigation. So did researchers at Harvard University.
“After the Human Genome Project, scientists found that there were around 20,000 genes within the genome, a number that some researchers had already predicted. Remarkably, these genes comprise only about 1-2% of the three billion base pairs of DNA. This means that anywhere from 98-99% of our entire genome must be doing something other than coding for proteins,” they wrote in a blog post.
“Imagine being given multiple volumes of encyclopedias that contained a coherent sentence in English every 100 pages, where the rest of the space contained a smattering of uninterpretable random letters and characters. You would probably start to wonder why all those random letters and characters were there in the first place, which is the exact problem that has plagued scientists for decades,” they added.
Not only is junk DNA an interesting study subject, but ongoing research may also produce useful new biomarkers for genetic diagnostics and other clinical laboratory testing. Thus, medical lab professionals may want to keep an eye on new developments involving non-coding DNA.